Index
Introduction🔗
OpenSAFELY is designed to allow you to do your analytic work on your own computer, without ever having to access the real, sensitive, patient-level data.
This tutorial will walk you through the minimum steps needed to run an OpenSAFELY-compliant study against "dummy" (randomly-generated) patient data. We ask all potential collaborators to successfully complete this tutorial, before applying to run their project against real data.
Please don't be afraid to ask questions in our Q&A forum!
Requirements🔗
The requirements for this tutorial are minimal.
You will need a computer with:
- an up-to-date web browser
- an internet connection
The tutorial will be completed in the GitHub Codespaces environment. Free GitHub accounts are given a monthly quota of Codespaces. If you do not have a GitHub account, we will create one in this tutorial.
Running OpenSAFELY🔗
1. Set up GitHub🔗
To use OpenSAFELY, you must have a GitHub account. GitHub is a widely-used
website for storing and collaborating on software, using the version control
software git. GitHub is where your open, reproducible research will be
published.
This tutorial also uses GitHub Codespaces to work with OpenSAFELY.
Creating a GitHub account🔗
Note
If you already have a GitHub account, you can use that account.
If you do not already have a GitHub account, you should create one first.
Visit GitHub and click the "Sign up" button. You will have to provide an email address and password. GitHub will also send you a confirmation email containing a link that you need to visit to confirm your account.
Securing your GitHub account🔗
We recommend that you secure your GitHub account with two-factor authentication.
2. Create a new repository in GitHub🔗
Here, you'll copy our OpenSAFELY research template to your own GitHub account, for developing your own study:
- Click on the link below to create new repository based on our template.
You may need to log in to GitHub if you are not already logged in:
https://github.com/opensafely/research-template/generate. - Use the Owner drop-down menu, and select the account you want to own the repository (typically under your own account)
- Type a name for your repository, and an optional description
- Choose a repository visibility. This would usually be "Public"
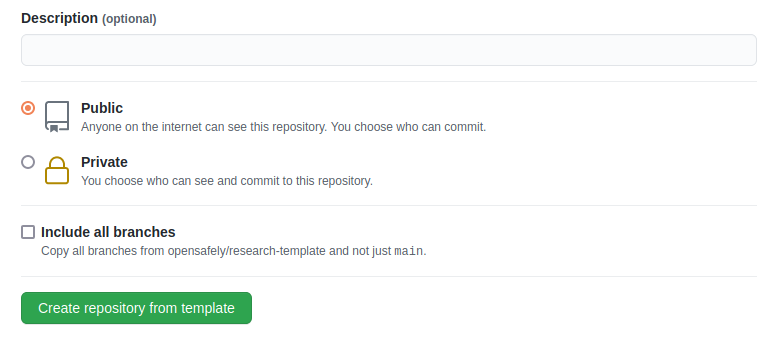
- There is an "Include all branches" option: this does not need to be selected. (You only need the main branch; the other branches are work-in-progress changes.)
- Click Create repository from template
- The new GitHub repository will take a moment to initialise, as it is running some setup in background. Wait about 1 minute, then reload the page, and you should see the README displayed now reflects the name you gave to the new repository.
- Once created, select the "Settings" tab and scroll down to the option to the option to "Automatically delete head branches". This should be turned ON so that when you merge a branch it is automatically deleted, keeping your branches neat and tidy. Deleted branches can be restored if needed later.
If you see ${GITHUB_REPOSITORY_NAME} in your README, the repo is not yet initialised, wait a few seconds longer and reload.
3. Open your repository with GitHub Codespaces🔗
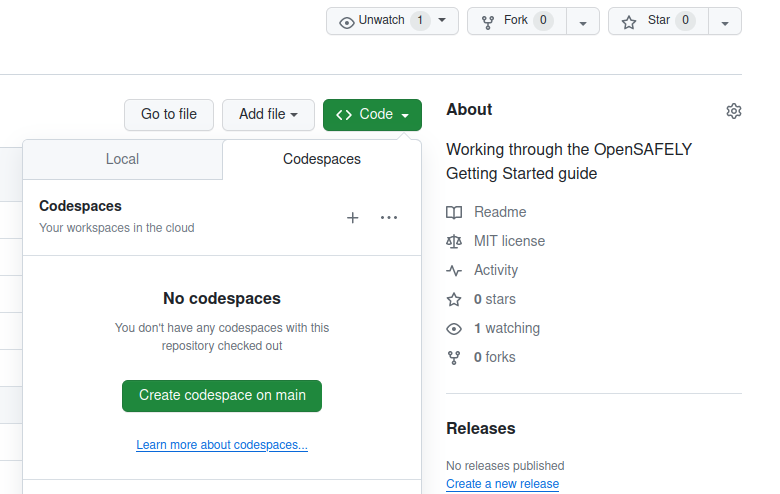
For the repository you just created, there is a Code button on GitHub.
To open your repository with GitHub Codespaces:
- Click the Code button.
- Click the Codespaces tab.
- Click the "Create codespace on main". The screenshot below shows this.
You should then see a "Setting up your codespace" screen:
A GitHub codespace containing the Visual Studio Code editor with a command-line interface "terminal" should then appear. This may take a little bit longer the first time a codespace is started, perhaps a minute or two.
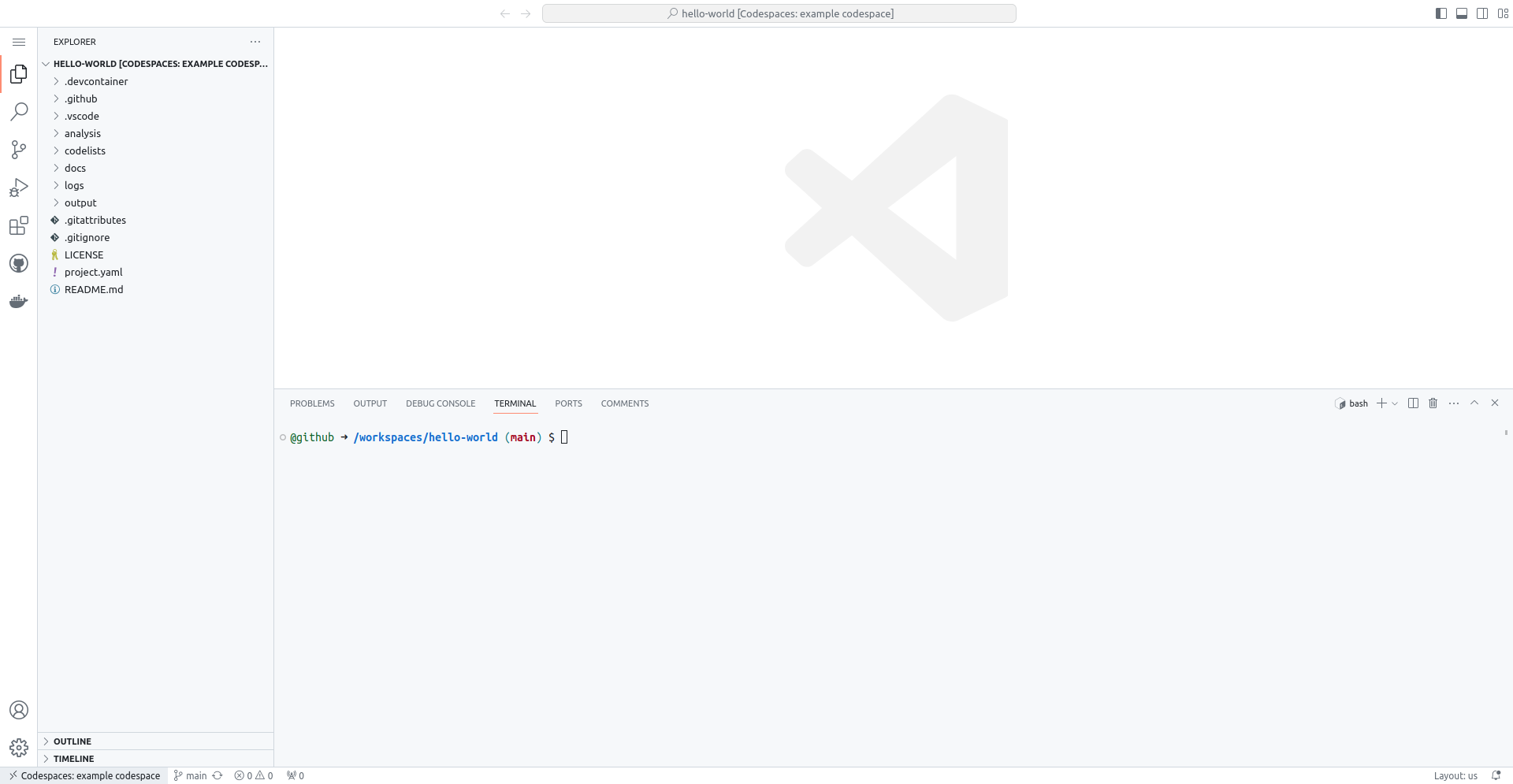
The terminal at the bottom-right of the GitHub codespace runs commands on a computer (virtual machine) provided by GitHub.
The large, upper-right area holds the main editor and where you will
view and edit files that you are working on. The left "side bar"
holds the Explorer when you first start the codespace. There are
other useful menus in this area that can be switched with the icons
to the far left side. Finally, the button at the top-left with three
horizontal lines (≡) is the menu button, which allows you to
access many more options.
If you find yourself using GitHub regularly for working on research, we have more information on working with GitHub codespaces.
Running opensafely🔗
The opensafely software should already be installed if you start
a GitHub codespace for the OpenSAFELY research template.
You can confirm this by typing opensafely in the terminal at the
prompt $ and pressing Enter. You should see an output that looks
something like:
$ opensafely
usage: opensafely [-h] [--version] COMMAND ...
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
available commands:
COMMAND
help Show this help message and exit
run Run project.yaml actions locally
codelists
Commands for interacting with https://codelists.opensafely.org/
pull Command for updating the docker images used to run OpenSAFELY studies locally
upgrade Upgrade the opensafely cli tool.
4. Try running the template study🔗
Run your first study🔗
Now you're ready to run your first study. Ensure your current directory is your newly-cloned study repository, and run:
$ opensafely run run_all
pressing Enter once you've typed the command.
The first time you run this command, it may take a while to download the required software. Eventually, you should see output that ends something like this:
<...several lines of output...>
generate_dataset: Extracting output file: output/dataset.csv.gz
generate_dataset: Finished recording results
generate_dataset: Completed successfully
generate_dataset: Cleaning up container and volume
=> generate_dataset
Completed successfully
log file: metadata/generate_dataset.log
outputs:
output/dataset.csv.gz - highly_sensitive
output/dataset.csv.gz, and that it should be considered highly sensitive
data. What you see here is exactly the same process that would happen on a real, secure
server.
This compressed CSV file contains a small amount of dummy data (patient ID and sex)
based on the dataset definition at analysis/dataset_definition.py.
To view it, first run opensafely unzip output, then open that
file (by left-clicking the filename in Visual Studio Code's Explorer, or
software like Excel). You'll see that it contains rows for ten
randomly-generated dummy patients.
Accessing files🔗
The Visual Studio Code editor has a file Explorer that you can use to browse the files and appears when first starting the GitHub codespace. It is accessed by the file icon in the bar on the left-hand side of the editor.
Clicking on a file name in the Explorer will open the file in a tab within the editor.
5. Make changes to your study🔗
You've successfully run the code in your study, but at the moment it just creates a nearly-empty output file. Now we'll add some code to do something slightly more interesting.
Add an age column🔗
- The "Explorer" on the left hand side lists the files and folders in
your research repository. Find and click on the
dataset_definition.pyfile inside theanalysisfolder. This file contains a dataset definition, specifying the population that you'd like to study (dataset rows) and what you need to know about them (dataset columns). It is written in ehrQL. - Add some text so that the file looks like this (new text highlighted):
Lines 8-12 mean "I'm interested in all patients who were registered at a practice on the index date"; line 14 "Give me a column of data corresponding to the sex of each patient"; and line 15 "Give me a column of data corresponding to the age of each patient on the given date".
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from ehrql import create_dataset from ehrql.tables.tpp import patients, practice_registrations dataset = create_dataset() index_date = "2020-03-31" has_registration = practice_registrations.for_patient_on( index_date ).exists_for_patient() dataset.define_population(has_registration) dataset.sex = patients.sex dataset.age = patients.age_on(index_date) - If you run:
$ opensafely run run_all
you'll see the command does nothing (because there's already a file at output/dataset.csv.gz):
=> All actions already completed successfully
Use -f option to force everything to re-run
We can use the --force-run-dependencies (or -f) option to force
the CSV file to be created again.
$ opensafely run run_all --force-run-dependencies
A new dataset.csv.gz file will be created in the output folder.
Add a chart🔗
Every study starts with a dataset definition like the one you just edited.
When executed, a dataset definition generates a compressed CSV (.csv.gz) of patient data.
A real analysis will have several further steps after this. Each step is defined in a separate file, and can be written in any of the programming languages supported in OpenSAFELY. In this tutorial, we're going to draw a histogram of ages, using either four lines of Python or just a few more lines of R.
- Right-click on the
analysisfolder in the editor's Explorer and select "New file". Type "report.py" as the filename and press Enter. - Add the following to
report.py:.import pandas as pd data = pd.read_csv("output/dataset.csv.gz") fig = data.age.plot.hist().get_figure() fig.savefig("output/descriptive.png")
- Right-click on the
analysisfolder in the editor's Explorer and select "New file". Type "report.R" as the filename and press Enter. - Add the following to
report.R:.library('tidyverse') df_input <- read_csv( here::here("output", "dataset.csv.gz"), col_types = cols(patient_id = col_integer(),age = col_double()) ) plot_age <- ggplot(data=df_input, aes(df_input$age)) + geom_histogram() ggsave( plot= plot_age, filename="descriptive.png", path=here::here("output"), )
This code reads the CSV of patient data, and saves a histogram of ages to a new file.
-
Open
project.yamlin the editor. This file will be near the end of the list of files and folders. This file describes how each step in your analysis should be run. It already defines a singlegenerate_datasetaction which defines the output that we've generated so far. This file is in a format called YAML: the way it's indented matters, so be careful to copy and paste the following carefully. -
Add a
describeaction to the file, so the entire file looks like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
- Line 14 tells the system we want to create a new action called
describe. - Line 15 says how to run the script (using the
pythonorRrunner). - Line 16 tells the system that this action depends on the outputs of the
generate_datasetbeing present. - Lines 17-19 describe the files that the action creates. Line 18 says that the
items indented below it are moderately sensitive, that is they may be released
to the public after a careful review (and possible redaction). Line 19 says that
there's one output file, which will be found at
output/descriptive.png.
At the command line, type opensafely run run_all --force-run-dependencies and press
Enter. This should end by telling you a file containing the histogram has been created.
Open it — you can do this via Visual Studio Code's Explorer — and check it looks right.
Warning
Changes you make to files are automatically saved on GitHub. However, changes will not persist outside of the GitHub codespace unless you commit and push them to GitHub, as described in the next section.
6. Test your study on GitHub🔗
Now that your study does something interesting, you should "push" it to GitHub, where it can be viewed by others. Your repository is automatically configured with tests to verify the project is runnable, each time you push.
In this section, you will first add the study changes that you've made to a new commit in your repository — a commit represents a stored version of your work — and then send that commit to GitHub by pushing the new commit.
Add your changes to the local repository🔗
(If you know how to use command-line Git, this works within GitHub's terminal if you do not want to use Visual Studio Code's Source Control feature.)
Back in the GitHub codespace, open the Source Control panel by selecting the icon that has round dots connected by lines on the left-hand side. It should be below the magnifying glass icon.
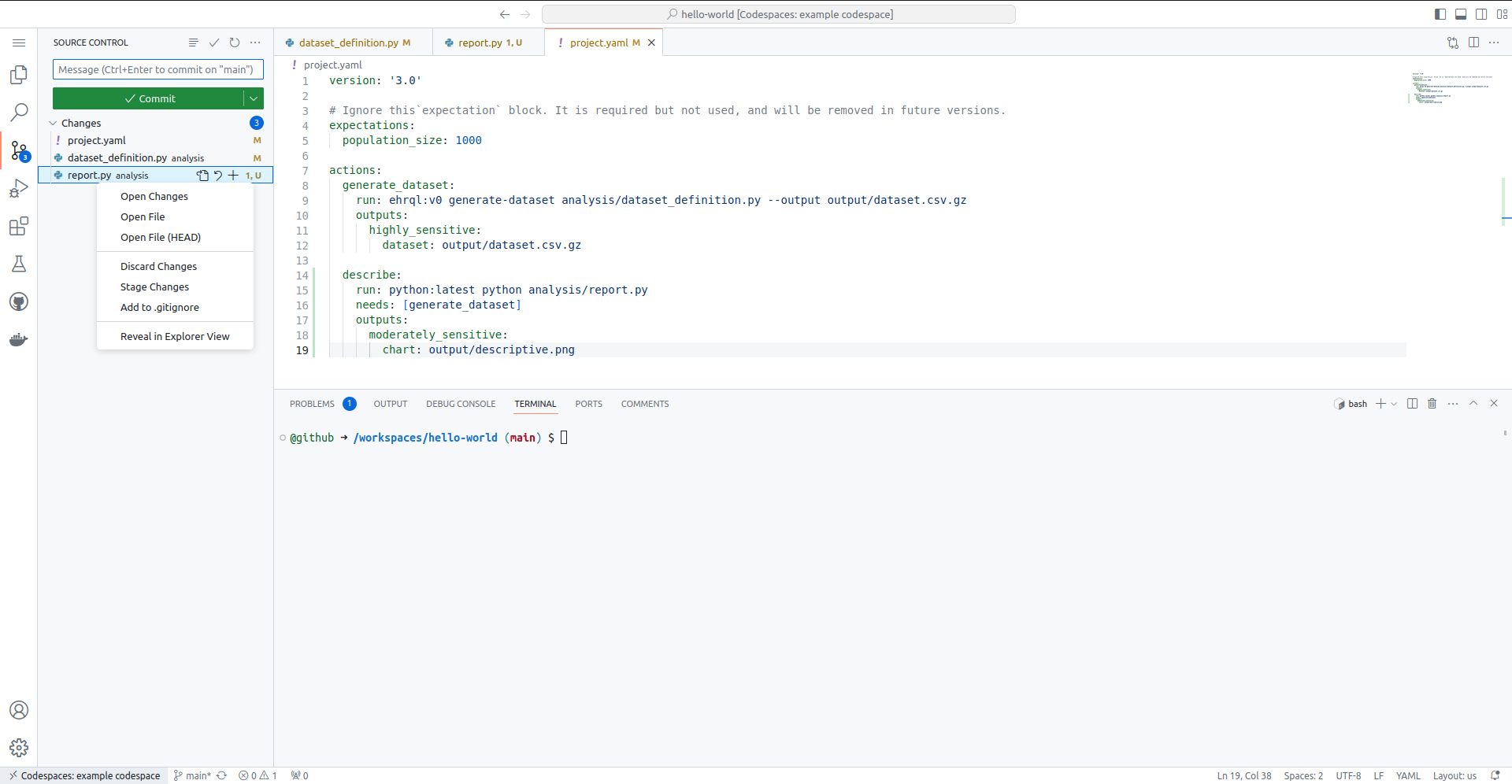
When files in the repository are edited and then saved, Source
Control should list those changes. Note that Visual Studio Code in
the codespace has Auto Save enabled by default. If you left-click on a file
in Source Control, you'll see how your copy of the file has changed
from the previous repository state. If you hover over a file in
Source Control under "Changes", you can propose to add the changes
to the repository by clicking the + icon next to the filename.
These "staged" changes then appear in the "Staged Changes" section.
Staged changes are changes that you are proposing to include in the next commit of this study repository. These could be modifications of existing files or entirely new files that you include.
It is also possible to "Discard Changes" if you accidentally stage a
file that you do not want to include. You can do this by hovering
over a file listed in the "Staged Changes" section and clicking the
- icon next to the filename.
When you've finished staging all your changes, you are now ready to make the new commit. Click the green Commit button, which will open and editor for you to type a commit message. Type a message to describe the staged changes. When ready, you can then click the tick icon to accept the commit message and commit the staged changes to to add them to the repository as stored in the codespace.
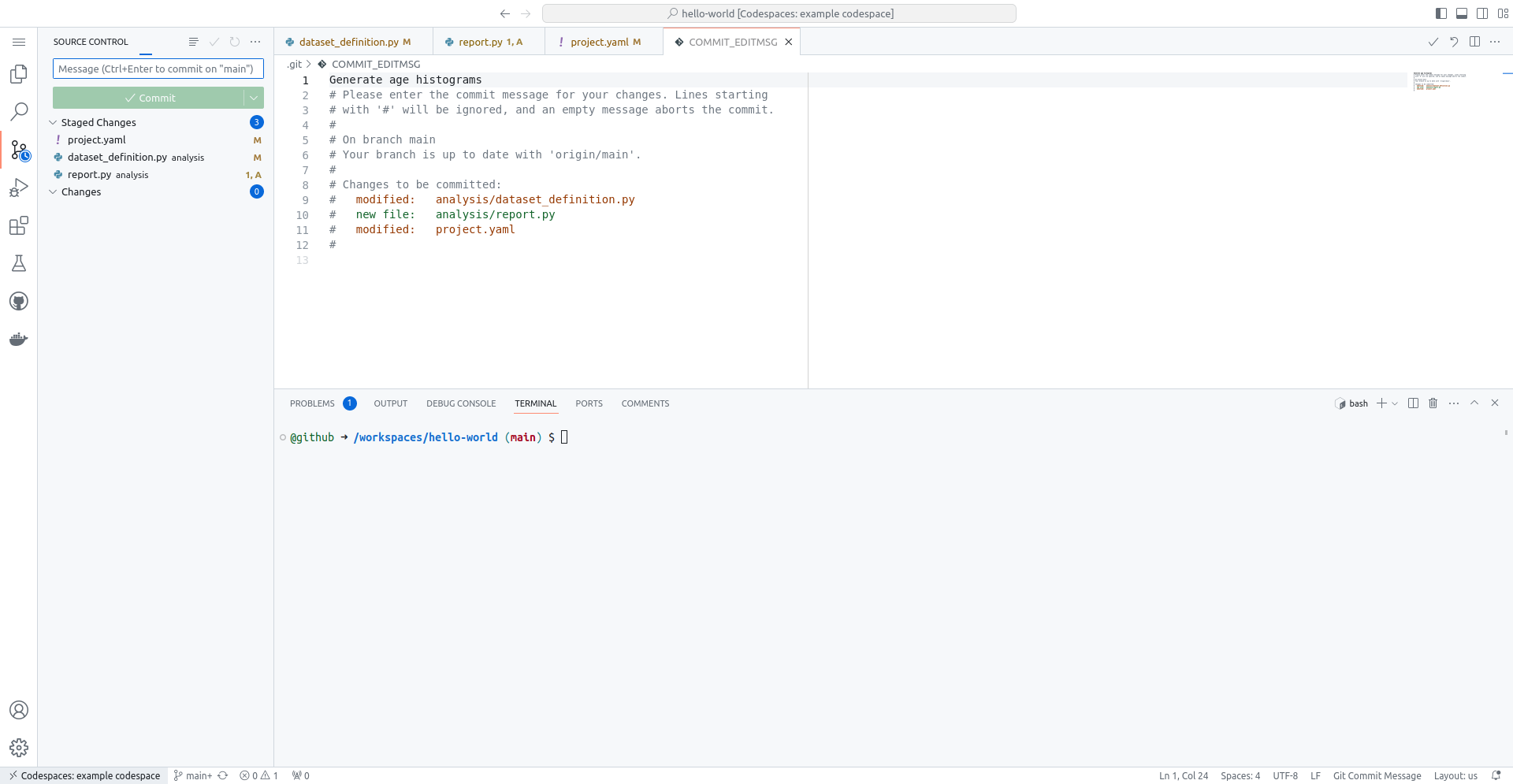
Push the changes to GitHub🔗
The changes have been stored as a new commit in the codespace's local copy of the repository. We now need to push the repository to GitHub to make the changes show up there.
Click the "Sync Changes" button to push your commits. Alternatively,
click the ellipsis (⋯) icon next to "Source Control" and then select
"Push". This should submit your changes to the GitHub repository that
you created earlier.
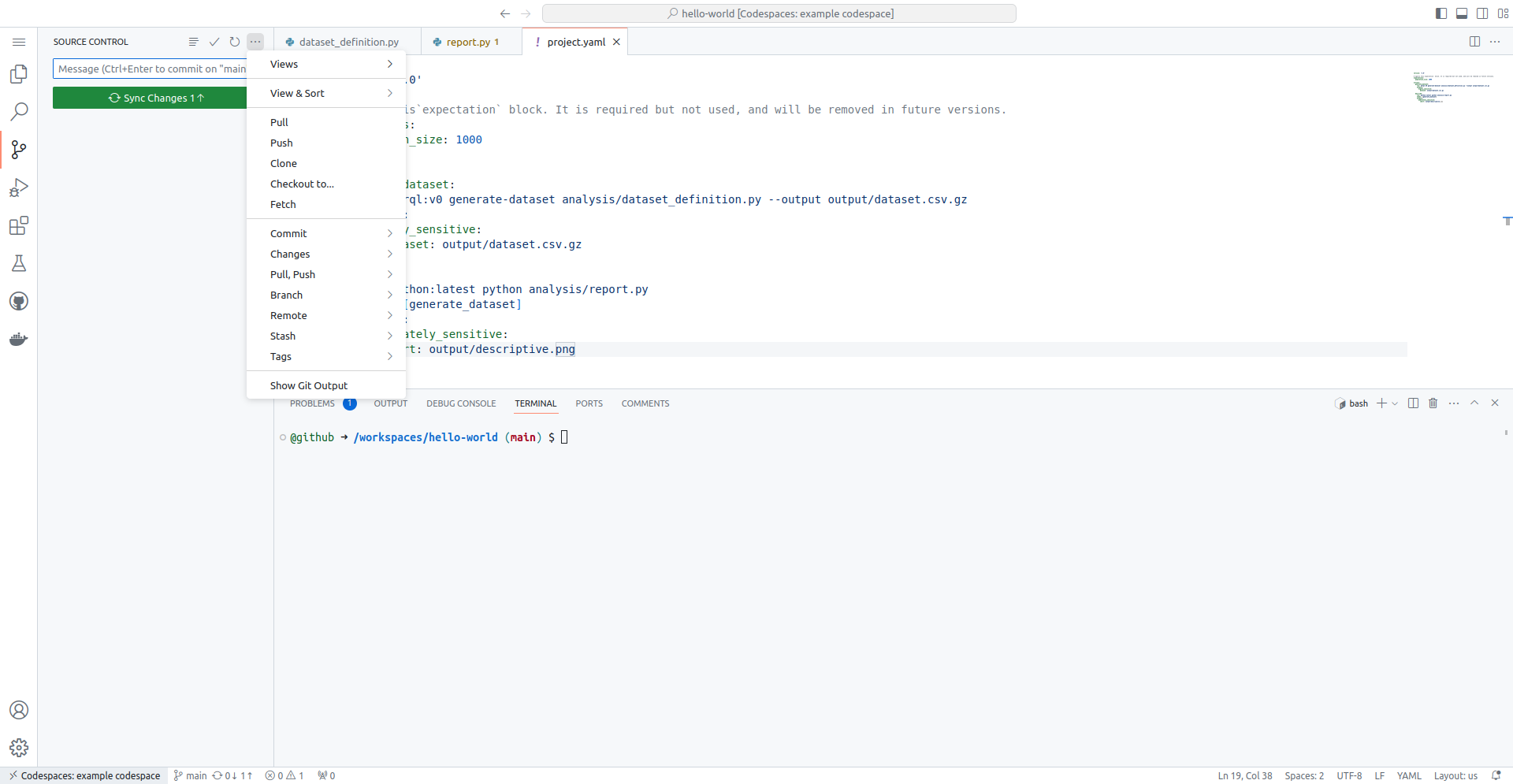
You will see a prompt: 'This action will pull and push commits from and to "origin/main".' — click OK.
(You may see a prompt: "Would you like Code to periodically run git
fetch?" You can ignore this or select "Ask me later" for the
purposes of this demonstration.)
Check that the automated tests pass🔗
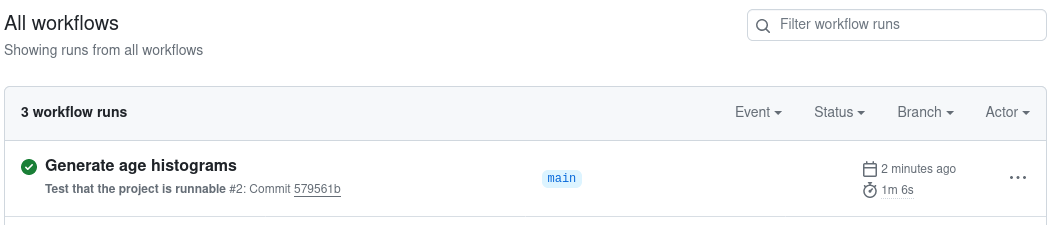
Visit your repository on GitHub's site. Click on the Actions tab
You'll see a Workflow running with the commit message of your last
commit. The workflow verifies that the command opensafely run run_all can
run successfully. If it's yellow, it's still running. If it's red, it
has failed. If it's green, it has succeeded. You want it to be green!
7. Tidy up🔗
If you close a Codespace in your browser, it still continues running. So, once you've finished using your Codespace, you may want to stop or delete it. There's information about how to do this on our Codespaces page.
8. Next steps🔗
Congratulations! You've covered all the basics that you need to develop a study on your own computer, verify that it can run against real data, and publish it to GitHub.
To write a real study and run it against actual patient data, you will first need to get permission for your project from the data controllers for the NHS England OpenSAFELY COVID-19 service.
Read about our pilot onboarding programme.
Once approved, your GitHub user account will be added to our opensafely GitHub organisation, along with your study repository, which gives you the ability to run your study against real data. Read more about permissions.
In the meantime, take a look at the rest of our documentation for more detail on the subjects covered in this tutorial. For example:
- There is a more complete guide to the OpenSAFELY command-line tool.
- The ehrQL documentation contains a tutorial for ehrQL, as well as a complete schema reference.
- You'll find more information about the contents of
project.yamlin the Actions reference. - OpenSAFELY walkthroughs (see this notebook) to guide you through the platform workflow on your own computer with dummy data, rather than using the documentation pages alone
- There is a final step we've not described here: a website called the "OpenSAFELY Job Server" where you can submit your repository actions to be run automatically within the secure EHR vendor environments. Right now you can only use this to run real jobs, but we're working on adding the ability to test your repository against dummy data.
- You'll be using
gitand GitHub a lot, and it's a critical but complex part of the OpenSAFELY ecosystem. If you're not familiar with these concepts, it's a good idea to read our git workflow page and its linked content.